I’m sorry to be asking such a basic question, but after some time spent in the help section at skritter.com and searching forum topics, I can’t seem to find what I’m looking for.
Basically, I’d like to know what happens if you add a new list that has a lot of overlap with previous lists.
In my particular example, I’ve finished studying my 5500-character Chinese list, and I just found an Anki deck with 6000 characters supposedly in order of common usage (my deck has a lot of characters which may not be in current usage, period).
I’d like to create a new list based on this Anki deck, but obviously most of it is characters I’ve already learned, so I don’t want to go back through all those again. Ideally I’d just want to add all the characters in this new deck to my current Skritter list, but I have no idea how to even begin approaching that, so instead, if I just add the new list to my queue, does Skritter recognize the characters I’ve already cleared and just add the ones I haven’t? How does that work?
Also, would adding a list with redundant entries affect my edits to my other list? I’ve done hundreds or possibly thousands of edits to my current list, and I would absolutely hate to lose all of that work. Otherwise I’d just zap the old list altogether and start over with the new one.
So really there’s two questions here: 1) Does anybody know of an easy method I could use to figure out the discrepancies between the old list and the new one, and just add the missing characters to the old one? That would be best, or failing that, 2) What if I just add the new list? What exactly happens to my study queue after that?
Thanks. I hope I’ve explained this question clearly enough.
Words are tracked system wide regardless of which list they came from, so adding the same words/characters to another list will have zero impact on when they are due. If a word isn’t due yet, it’s not due, even if it’s in a new list you’re studying. Here’s an excerpt from a guide on the SRS:
The system automatically keeps track of duplicate words and makes sure that you don’t see them more often, even if you add them from several lists. In a nutshell: you don’t need to worry about duplicates-- it’s under control!
Thanks Jeremy. So, if I understand this correctly, I could add a new list, the system would start at the beginning in the first bloc of (probably 200) terms, and just skip over everything already in my queue, and continue using the custom definitions where I’ve entered them?
Nevermind. Decided to blow a morning learning how to compare 2 .csv files for discrepancies. The original list has been updated and now contains something on the order of 6500 single characters.
Quick question: a lot of these characters are lacking definitions of any sort. I have a few textbooks and dictionaries from various decades, so over time I expect to be able to populate some of those fields. But by adding my own definition edits, does that save to my published list so that others who decide to study it later can benefit from this editing, or do they have to start all over from scratch with the defaults?
If a word doesn’t have an English definition yet, or it’s a word you’ve created, then others would see the definition you created if they study the word (even if that same word is in a different list-- word edits are system wide and not per list). If you make any edits to an existing definition though, that would be a personal edit which only you would see. If you think it warrants being a correction that everyone should see, you could submit the change as a “correction” which sends it to a queue to be looked over and either accepted or denied. The ability to submit a correction hasn’t been added into 2.0 yet though, so you’d need to use the legacy site to submit them.
Is there a way to submit a correction for words that are given an apparently incorrect pronunciation? In this latest batch of characters I’ve added to my list, there are a sizable number of them ranging in obscurity from advanced to unknown that are all defined as “chuà,” which not only isn’t even a Chinese syllable (might be Cantonese), but when I look up these characters, they’re typically listed with some other pronunciation.
As an example, in the bloc of 200 characters currently being added to my queue, I found all these characters listed as “chuà:” 叡, 佮, 篠, 葔, 抴, 葾, 梖, 咁, 踼, 烸, 槙. Almost all of those can be found either at Youdao, Pleco, or MDBG.
You can send a correction report explaining the pinyin change in need, sure! Characters that show up with the reading “chua” are defaulting to that as a placeholder, which means those characters were somehow added without a pronunciation. I can edit these for you, would you be able to easily paste the block of 200 characters that don’t have readings set up correctly?
I don’t have an entire bloc of “chua” characters, what I meant was that in the group of 200 (the max you can add at a time to a list) out of maybe 5 that I just added, there were these 11. I can scan through the other added blocs to copy any more that I find. If you just want all the “chuas,” I can probably get it done in about 15 minutes. Should I just paste them in here? In general, submitting a formal individual correction report is no problem, but we’re talking about a lot of individual characters.
In case this is the place to put it, I found a total of 100 more chuas, and since the time-zone difference gives us about a day’s turnaround on these threads, I’ll just paste them in here for now, and if you want me to submit them somewhere else, I can do that too. So, for your consideration, here’s some interesting characters:
Well, the undefined terms wouldn’t add to the queue, so I ended up in a weird situation where the list reports as “finished” although there may be a hundred or so characters that I haven’t studied yet. So I spent a few days looking up all the chuas and filling in the blanks, with a note as to correct pronunciation included at the top.
I gather it won’t be possible to change the pronunciation field until everything is migrated to 2.0, but when the time comes, maybe it’ll be a quicker job with some of the ground work done. Aside from a few characters that had multiple pronunciations listed, I feel pretty solid about the accuracy of the entries, as far as the various Chinese dictionary websites and character archives agree on the meanings and pronunciations. Pretty solid.
I’ve made sure the pronunciation field is added to each of the characters you’ve listed (and removed the pr. portions from the definitions), except for 絣, 鞥, and 掅 which I couldn’t find information for. Would you be able to provide the info for those three characters?
Also, I recommend resetting the list these character live in back to the beginning so it can rescan them over.
I was able to find listings for those characters at http://iccie.tw/ (dictionary search bar is right at the top of the page) It seems most of these websites pull definitions from a common archive, so other sites like http://www.hanzizidian.com/ and http://ctext.org/dictionary.pl?if=en tend to yield identical results.
When you say resetting the list back to the beginning, do you mean doing the scorched earth thing at the legacy site? At this point I’d prefer to avoid that, or at least for the time being.
After restoring subscription and data on my phone, and then reinstalling the app completely, it looks like all the missed terms are adding back in although my “items due” counter is currently having some kind of meltdown (described on the thread dedicated to that issue), and I’ve also found a handful of straggler chuas that still need editing, which I’ll list here:
篠 咁 踼 傱 荖 媜 掅 潳
As well, there are a quite a few more entries with my pronunciation notes still left in. I can of course edit those out for my own personal use, but anyone studying this list will have to do it for themselves too. I can compile a list of those entries, but it might take a bit more time.
OK, here’s a list of all the new entries I could find that have had the pronunciation fields corrected but still show my pronunciation notes in the definitions fields:
Which easily looks like most of them. I’m guessing there might be some problems getting things to stick in the editor. Anyway, I corrected a few entries on my app here before realizing what had happened, which means I’m unable to see all the entries where the fixed definitions didn’t take. It’s not many, but it might be a bit of a needle in a haystack kind of situation. Sorry about that, I thought including the pronunciations would make the job of editing easier for you when the time came.
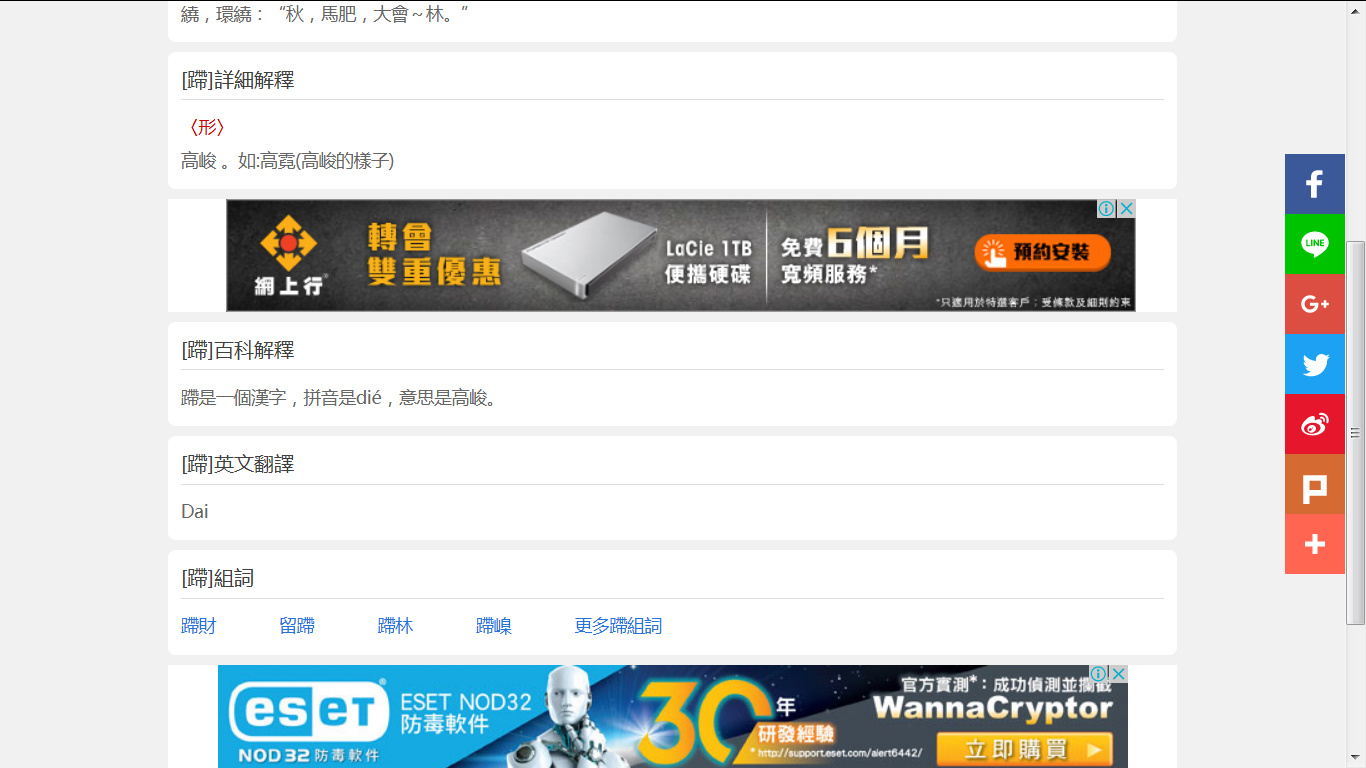
One more item, and I just accidentally noticed this, but there’s a discrepancy for the character 蹛. The corrected pronunciation entry shows die2 but when I look it up it consistently shows dai4 http://iccie.tw/q/蹛 Don’t know if that means you have a lookup resource that disagrees with my findings, or if it was just a typo, so I thought I’d mention it.
@pts Because there can be multiple listed pronunciations even for modern characters which in actual usage overwhelmingly are pronounced in a single a certain way (in Mandarin, anyway), it made the most sense to me to go with a consensus from multiple sources. I don’t know what the utility is of learning 4 pronunciations for a character that hasn’t been in use for probably hundreds of years if 5 different sources only agree on one pronunciation.