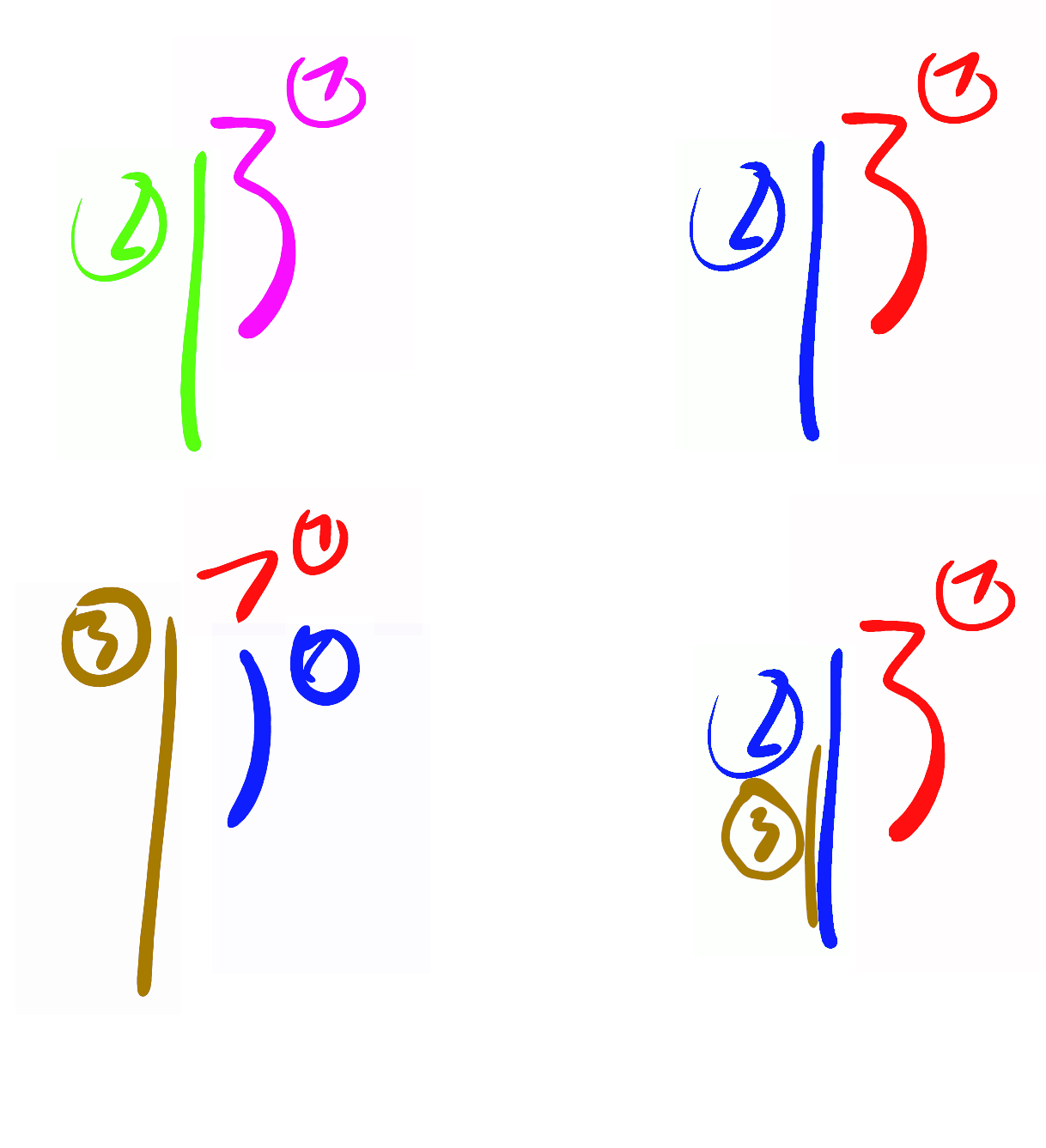
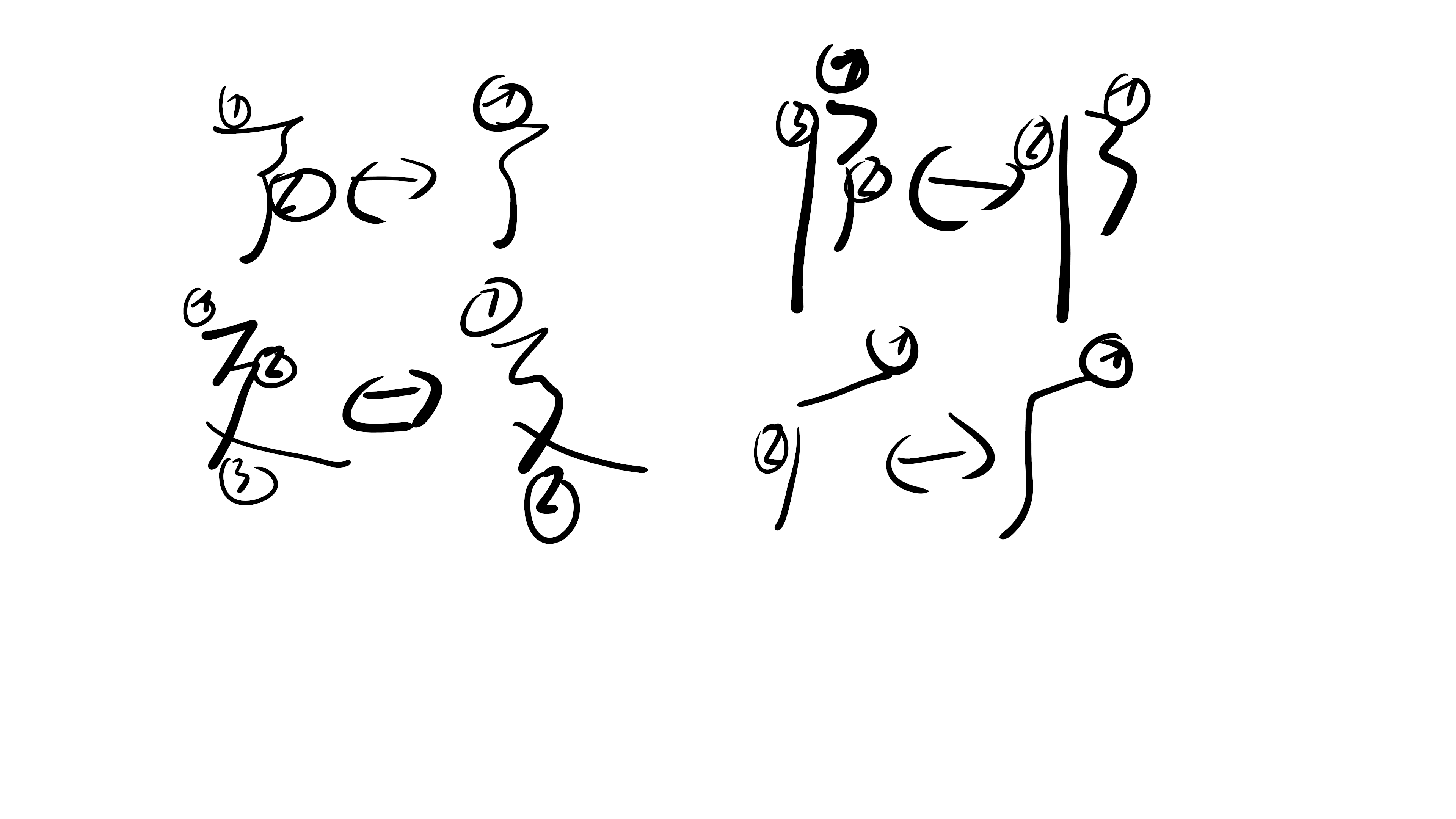This is most definitely a bug of your recognition algorithm. As it picks the wrong one. I cannot fathom by which definition of a bug you go, but I as dev definitely think an algorithm that does not work as expected is bugged. (expected here is defined by what your are trying to do, not by the incorrect behaviour of you algorithm)
As for how to solve this, you are taking the wrong approach. Rawest squigs is not solving the problem it is ignoring it. I do not understand why people would pay and use this website if they turn on rawest squids. If you do that you can literally achieve the same with anki for free. I have used that before I came here. Really the only thing you guys offer that one cannot achieve for free with little to no extra work is handwriting recognition. Pinyin? Anki can do keyboard input checking. Tones? either use text input as well or check in head. meaning? you are literally doing it equivalent to anki.
I am really sorry, but i seriously think you need to reevaluate your approach towards bugs. A while ago I reported that there are sync problems when often switching between the website and phone. How did you solve that back then?: You did not fix the bug instead you forced the bugged behavior always.
- the bug was: Because of desync of the app I had to wait a long time occasionally a long time for a sync to fix.
- Fix: always sync everything. Now I have to wait a long time every time. Every time i start the app, every time i finish a lesson/review session.
I have to do that a lot because I split my learning into smaller chunks. This irritated me a lot every day until i decided it is easier to just switch off my internet and only turn it on when i want to sync it. because of that i sometimes miss the audio for cards.
you guys seem to have a lot of technical debt and i think this is mostly caused by this attitute towards not properly fixing bugs but just making dirty workarounds. You really need to address your technical debt before you add more features. I am really worried that if you do not address your technical debt soon its gonna put you out of business.
Currently, out of the depth of my heart I cannot say that I would recommend your app as much as I wanted to. My experience as a power user has been extremely frustrating. And i hope I expressed this well and politely but with a tone that emphasises the importance of this. I am not here because I want to put you down, I am here reporting bugs because I want to help you. And i can advise you this: Focus on what makes you different from competitors. There are so many apps the teach kanji with pictures, videos etc. You do not need this. What you really need is that when a user comes onto your platform is that they have the best experience with what makes you distinctive: Kanji/Hanzi writing.
Please before doing anything extra, focus on your core experience and get that perfect.
Now back on topic:
It seems that currently you currently your algoritm only judges written strokes based on the user input for that stroke as well as all previously recognised stroken. Consider changing this to the following, instead of disgarding, keep the heuristic data for all previous stroken and upon the user writing the next stroke reevaluate the previous strokes based on that. This would allow you to retrospectively correct strokes that were incorrectly recognised. Yes I am aware that this drastically increases the amount the search space, but you limit evalutation to the last 4 strokes, so that would only complicate the search by 4! So it would take 24 times longer in the worst case, which i do not think is possible. If you need help implementing that algorithm I can help.
Cheers and best wishes
sirati